
PV统计demo:
1.PvCollectSpout.java
先定义PvCollectSpout,主要作用是从kafka中读取消息,并把读取到的消息传递到bolt中。
public class PvCollectSpout extends BaseRichSpout{ private static Logger logger = LoggerFactory.getLogger(PvCollectSpout.class); public static final String ID = "PvCollectSpout"; public static final String OUTPUT_FIELD = "PvCollectSpoutOutPutField"; private SpoutOutputCollector collector; private KafkaConsumer kafkaConsumer; private Properties kafkaConsumerProperties = new Properties(); private static final String BLACKSTONE_ZK_SERVER = "kafka依赖的zk配置"; private static final String BROKER_SERVER = "kafka依赖的zk配置"; private static final String WX_LOG_TOPIC = "wx_universal_track_page_v1_log"; private static final String RECOMMEND_GROUP = "wx_community_recommend_group"; public PvCollectSpout() { kafkaConsumerProperties.put("zookeeper.connect", BLACKSTONE_ZK_SERVER); kafkaConsumerProperties.put("metadata.broker.list", BROKER_SERVER); kafkaConsumerProperties.put("rebalance.max.retries", "5"); kafkaConsumerProperties.put("rebalance.backoff.ms", "2000"); kafkaConsumerProperties.put("auto.offset.reset", "largest"); } /** * 初始化数据源 * @param map * @param topologyContext * @param spoutOutputCollector */ @Override public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) { this.collector = spoutOutputCollector; this.kafkaConsumer = new KafkaConsumer(RECOMMEND_GROUP, kafkaConsumerProperties); } /** * 把tuple发送至下游 */ @Override public void nextTuple() { try{ String log = kafkaConsumer.get(WX_LOG_TOPIC); Values values = new Values(log); collector.emit(values); } catch (Exception e) { logger.error("spout发送数据失败",e); } } /** *定义输出字段 * @param outputFieldsDeclarer */ @Override public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { outputFieldsDeclarer.declare(new Fields(OUTPUT_FIELD)); }} 2.PvCollectBolt.java
再定义PvCollectBolt,读取从Spout中流入的数据,并进行pv数据清洗,然后把数据存储到tair中。
public class PvCollectBolt extends BaseRichBolt { public static final String ID = "PvCollectBolt"; private static Logger logger = LoggerFactory.getLogger(PvCollectBolt.class); private static final String TAIR_MASTER = "tair集群节点配置"; private static final String TAIR_SLAVE = "tair集群节点配置"; private static final String TAIR_GROUPNAME = "tair集群节点"; private static final int TAIR_NAMESPACE = 564; private static final String RECOMMEND_PREFIX = "recommend_"; private OutputCollector collector; private DefaultTairManager tairManager; @Override public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) { this.collector = outputCollector; tairManager = new DefaultTairManager(); List configServerList = new ArrayList<>(); configServerList.add(TAIR_MASTER); configServerList.add(TAIR_SLAVE); tairManager.setConfigServerList(configServerList); tairManager.setGroupName(TAIR_GROUPNAME); try { tairManager.init(); } catch (Exception e) { logger.error("初始化tair失败:", e); } } @Override public void execute(Tuple input) { String out = null; try { out = input.getStringByField(PvCollectSpout.OUTPUT_FIELD); if (out.contains("pages/question/detail/index?qid") && out.contains("ptp=103.question_square")) { String[] valueList = out.split("\t"); Map urlParamMap = UrlUtils.URLRequest(valueList[9]); String qidString = urlParamMap.get("qid"); logger.info("小程序打点日志,qid:"+qidString); Long qid = IdConvertor.urlToId(qidString); incrTair(qid); } } catch (Exception e) { logger.error("执行pvCollectBolt失败!", e); } } @Override public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { } /** * incr */ private void incrTair(Long qid) { String key = RECOMMEND_PREFIX + qid; Result result = tairManager.incr(TAIR_NAMESPACE, key, 1, 0, 0); if (result.isSuccess()) { logger.info("围观人数收集:qid:{},resultValue:{}", qid, result.getValue()); } else { logger.error("围观人数收集失败: qid:{}", qid); } }} 3.PvCollectTopology
定义topology,主要设置数据流向并行度等,整个程序的入口,定义的main方法也是在topology中定义的 。
public class PvCollectTopology { private static final String TOPOLOGY_NAME = "PvCollectTopology"; /** * Storm的进程数量 */ private static final int WORKER_NUM = 1; /** * Storm的线程数 */ private static final int EXECUTOR_NUM = 2; public static void main(String[] args) throws Exception { TopologyBuilder builder = new TopologyBuilder(); //配置spout线程数 builder.setSpout(PvCollectSpout.ID, new PvCollectSpout(), EXECUTOR_NUM); //配置bolt线程数 builder.setBolt(PvCollectBolt.ID, new PvCollectBolt(), EXECUTOR_NUM * 3).shuffleGrouping(PvCollectSpout.ID); /** * 配置 */ Config conf = new Config(); //设置storm进程数 conf.setNumWorkers(WORKER_NUM); conf.put(Config.TOPOLOGY_WORKER_CHILDOPTS, "-Xmn64m -Xms256m -Xmx256m"); StormSubmitter.submitTopologyWithProgressBar(TOPOLOGY_NAME, conf, builder.createTopology()); }}
storm并行度:
先说并行度的几个概念。niumbus | supervisor | worker | executor | task
- niumbus 主控节点运行Nimbus守护进程,类似于Hadoop中的jobtracker,负责在集群中分发代码,对节点分配任务,并监视主机故障
- supervisor 工作节点,与nimbus控制节点对应,一般会对应一个服务器作为节点。
- worker 工作进程,我们在storm.yaml中为每个supervisor配置slot个数及端口,每个slot对应一个worker,每个worker会启动独立进程。
- executor 执行器,是在每个worker中启动的线程,完成具体的任务task。根据提交的拓扑中conf.setNumWorkers(3);定义分配每个拓扑对应的worker数量,Storm会在每个Worker上均匀分配任务,一个Worker只能执行一个topology,但是可以执行其中的多个任务线程。
- task则是一个任务实例,在executor中执行,一般来说与executor个数是一样的。
我们通过Storm UI 可以看下刚才我们demo的并行度
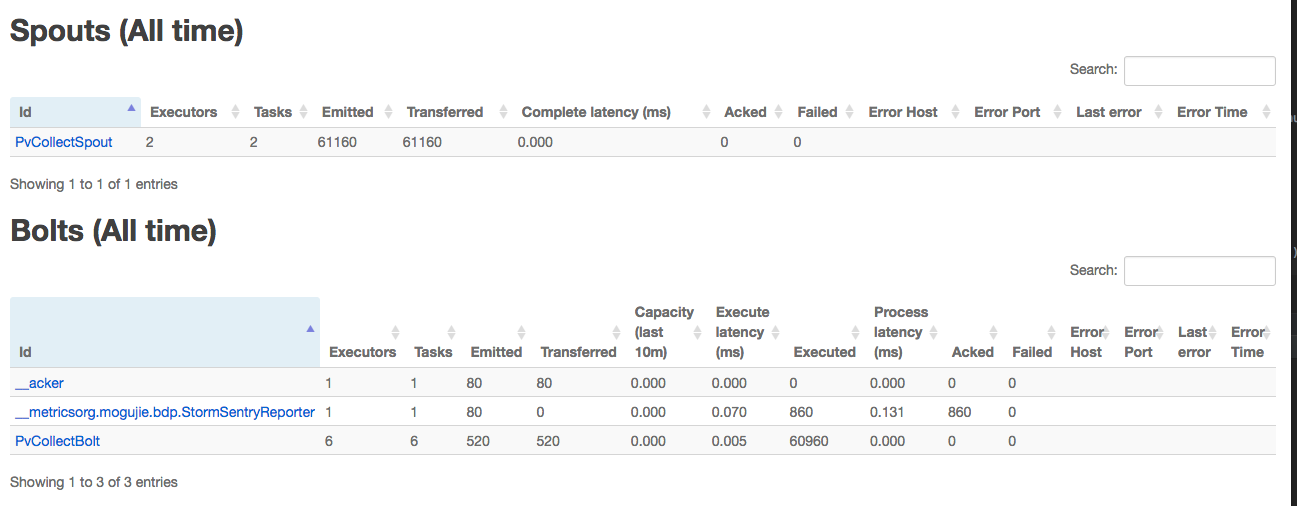
通过storm UI可以看到,我们现在整个topology中spolt占用2个线程,bolt占用6个线程,和我们在代码中的设置是一样的.
关于并行度数值的设置:
主要分两大类
一.全局的,通过在搭建storm集群时配置中完成,主要有两个:supervisor和worker。
在配置文件中设置的worker表示该supervisor机器运行几个进行。
二.topology使用,用代码设置,主要有三个:worker,executor和task。
在代码中设置的worker表示该topology使用到的进程数。
task不额外设置的话数量和executor相同。
Storm的容错机制:
1. Worker进程死亡
当仅有Worker进程死亡时,其主机上的Supervisor会尝试重启Worker进程,如果连续重启都失败,当超过一定的失败次数之后,Nimbus会在其他主机上重启Worker。
当Supervisor死亡时,如果某个主机上的Worker死亡了,由于没有Supervisor,所以无法在本机重启Worker,但会在其他主机上重启Worker,当Supervisor重启以后,会将本机的Worker重启,而之间在其他主机上重启的Worker则会消失,例如之前node2有三个Worker,node3有三个Worker,当node2的Supervisor死亡并且kill掉一个Worker之后,node3出现四个Worker,重启node2的Supervisor之后,node2会重启一个Worker,恢复成三个Worker,node3kill掉多余的一个Worker,也恢复成三个Worker。
当Nimbus死亡时,Worker也会继续执行,但是某个Worker死亡时不会像Supervisor死亡时安排到其他主机上执行,因此如果Worker全部死亡,则任务执行失败。
集群中的Worker是均匀分配到各节点上的,例如一个作业有三个Worker时,会在一个节点(例如node2)分配两个Worker,在一个节点(例如node3)分配一个Worker,当再启动一个需要三个Worker的作业时,会在node2分配一个Worker,在node3分配两个Worker。
2. Nimbus或者Supervisor进程死亡
Nimbus和Supervisor被设计成是快速失败且无状态的,他们的状态都保存在ZooKeeper或者磁盘上,如果这两个进程死亡,它们不会像Worker一样自动重启,但是集群上的作业仍然可以在Worker中运行,并且他们重启之后会像什么都没发生一样正常工作。
3. ZooKeeper停止
ZooKeeper的停止同样不会影响已有的作业运行,此时kill掉Worker以后过段时间仍会在本机重启一个Worker。
综上所述,只有Nimbus失败并且所有Worker都失败之后才会影响集群上的作业运行,除此之外Storm集群的容错机制可以保证作业运行的可靠性。